Posts tagged 2-layer-transformer
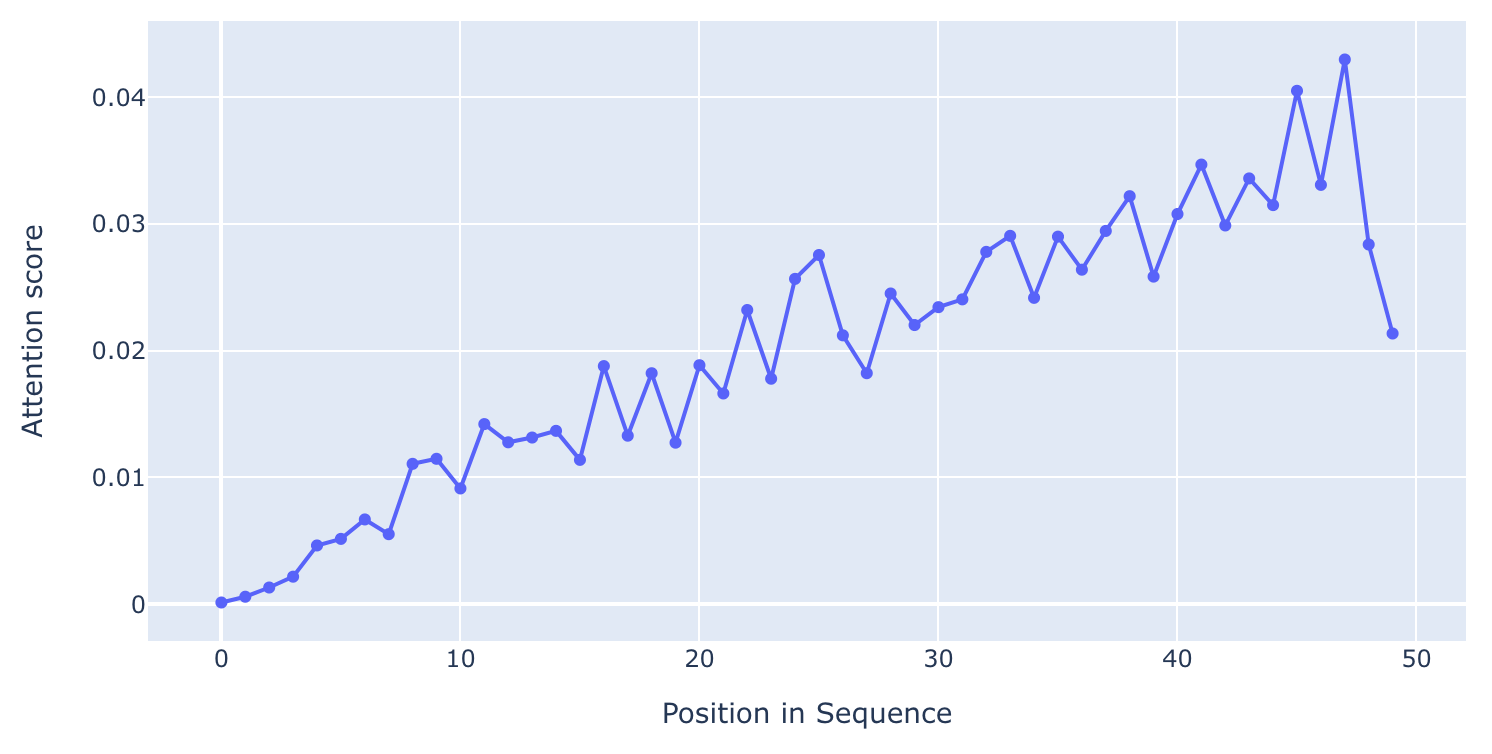
'Recency bias' in an induction head
The induction head in a 2-layer attention-only transformer model has a slight bias towards tokens later in the context compared to earlier. Interestingly, its notion of position appears to not depend on positional embeddings, or any specific output from an attention head in the previous layer.
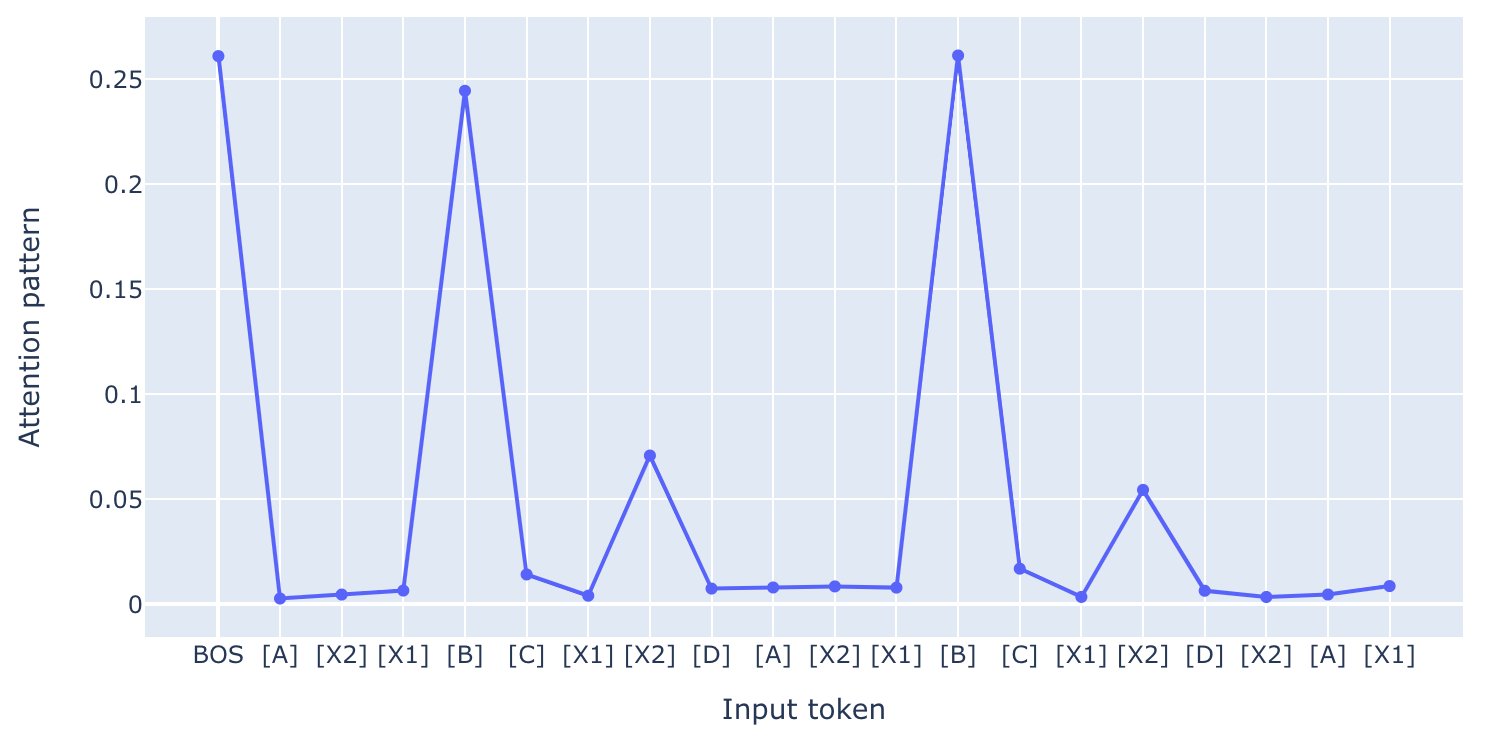
Induction head circuits for longer sequences
In a 2-layer attention-only transformer model, an induction head can combine with an "averaging" head that stores some kind of average over the previous ~4-5 tokens to produce a circuit that can predict the next token in repeated sequences of length 2 to 5.
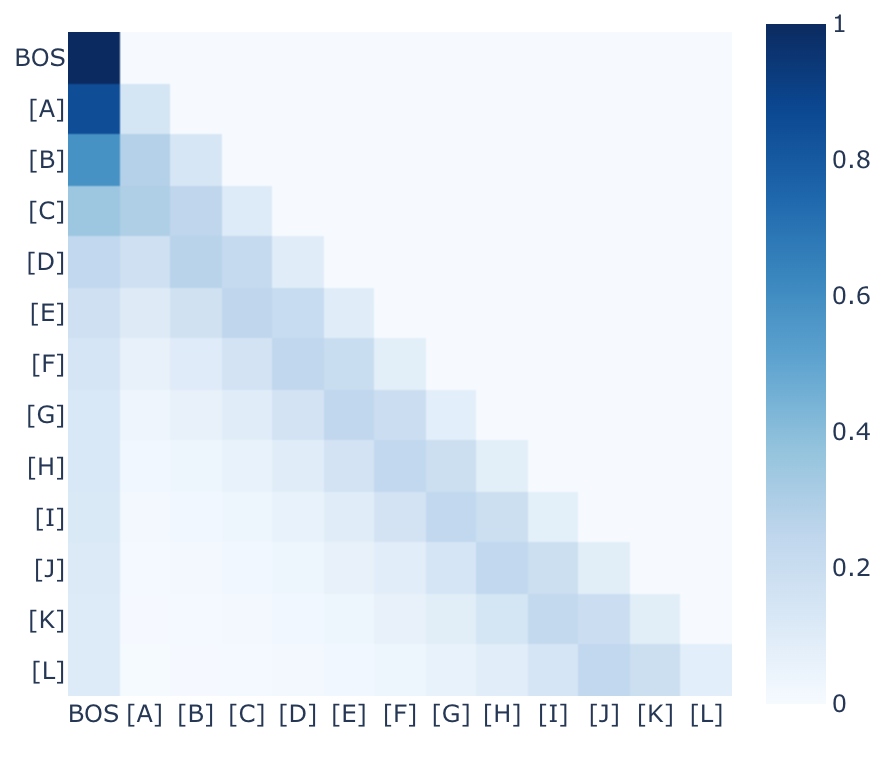
The previous token head and the "look-back-two" head
A few plots on previous token heads, a discussion of how they work and a comparison to a similar type of attention head -- a "look-back-two" head.
Positional Embeddings in a 2-layer attention-only transformer model
The position embeddings in a 2-layer attention-only transformer model arrange themselves into a helical structure. This presumably allows the model to generate QK matrices to move a few positions in relative terms with a similar transformation for all positions. The positional embeddings at positions 0 and 1023 have special properties.