All Posts
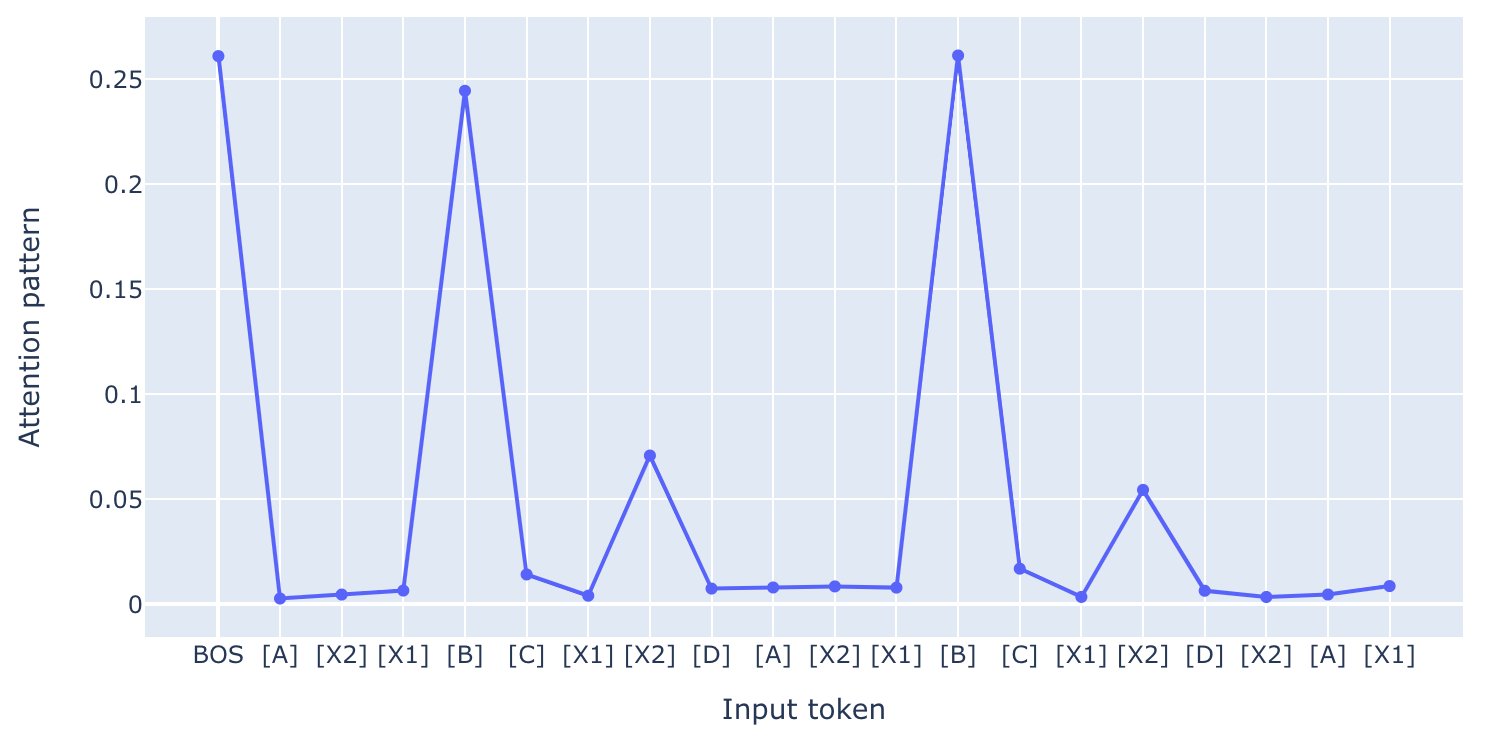
Is induction a memorized or generalized capability?
We probe whether the repetition capability of our toy transformer reflects genuine generalisation or memorisation of the training distribution. A single-token experiment reveals an apparent illusion of generalised induction, a cautionary finding for evaluations of larger LLMs.
How much data does a transformer need to learn repetition?
We systematically degrade the repetition signal in the training data, token by token, and row by row, and find a critical threshold below which induction heads cease to form. Even 10% of tokens in repeated sequences is enough.
Token distribution drives repetition learning
We surgically replace the tokens inside repeated sequences with random tokens, while keeping the sequence structure fixed to investigate the impact on repetition performance.
Is natural language special for learning repetition?
We reverse all tokens in the Pile dataset and find that a transformer trained on completely unnatural data still learns to repeat sequences suggesting linguistic structure is not required for induction head formation.
Repetition is surprisingly ubiquitous in tokenized natural language
55% of tokens in the tokenized Pile dataset are part of repeated sequences, defined as either A or B in ...AB...AB, and we characterise the structure of those repetitions in detail.
An introduction to our investigation into repetition capability in toy transformer models
Why we want to study repetition in toy transformer models and what we aim to investigate
Unlearning with sparse autoencoders
We trained sparse autoencoders on the open-source language model Pythia-2.8b to use for unlearning Harry Potter related knowledge. We can successfully unlearn significant levels of Harry Potter related knowledge with little to no side effects.
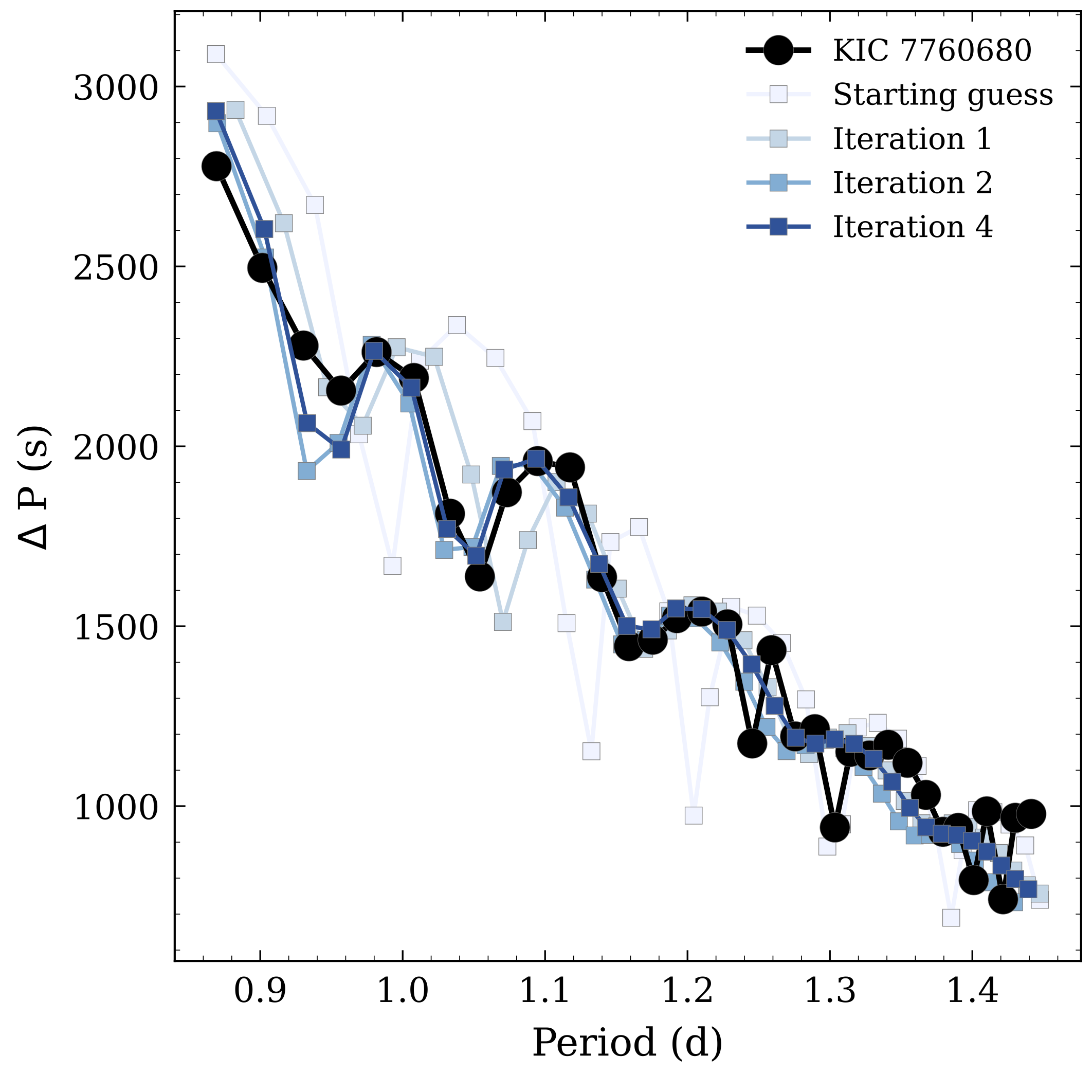
A method for non-linear inversion of the stellar structure applied to gravity-mode pulsators
Published in Farrell et al. (2024), Astronomy & Astrophysics, Volume 686
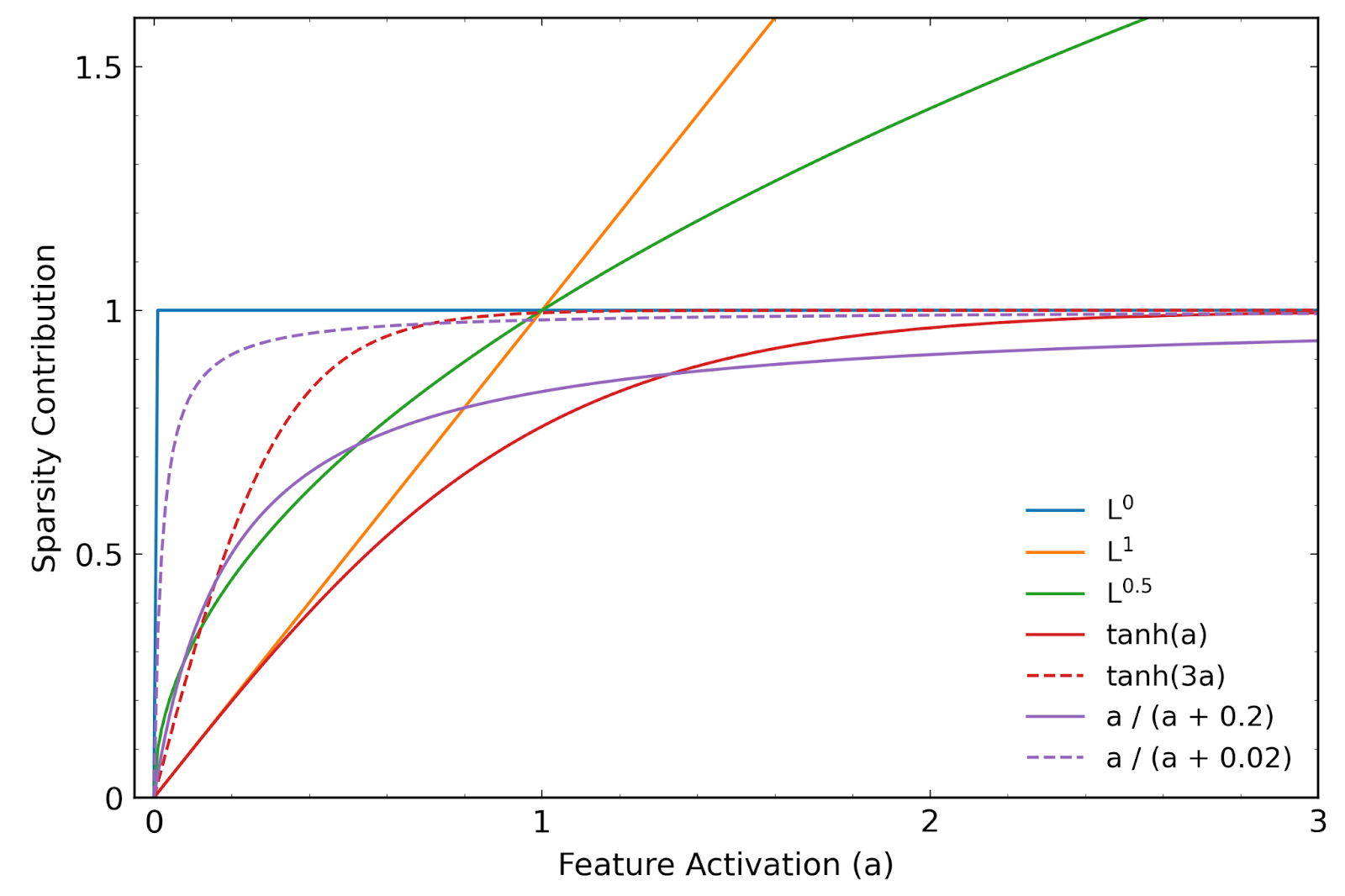
Experiments with an alternative method to promote sparsity in sparse autoencoders
I experimented with alternatives to the standard L1 penalty used to promote sparsity in sparse autoencoders (SAEs). I found that including terms based on an alternative differentiable approximation of the feature sparsity in the loss function was an effective way to generate sparsity in SAEs trained on the residual stream of GPT2-small.
Experiments with Sparse Autoencoders on Attention Heads
I trained sparse autoencoders on the key and query vectors of previous token heads and induction heads of attn-only-2l and gpt2-small and found interpretable features which I could intervene on in a predictable and interpretable way.
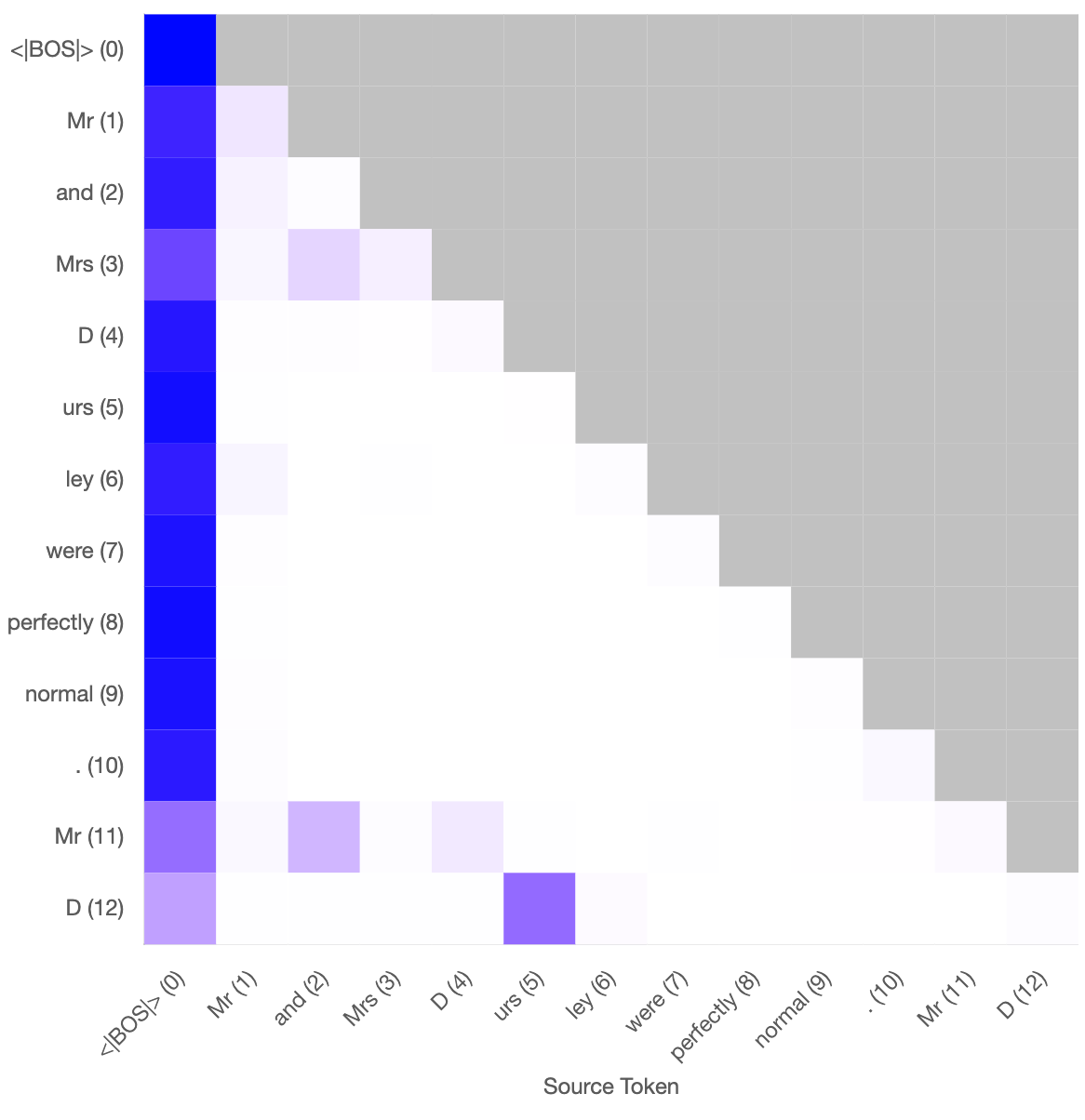
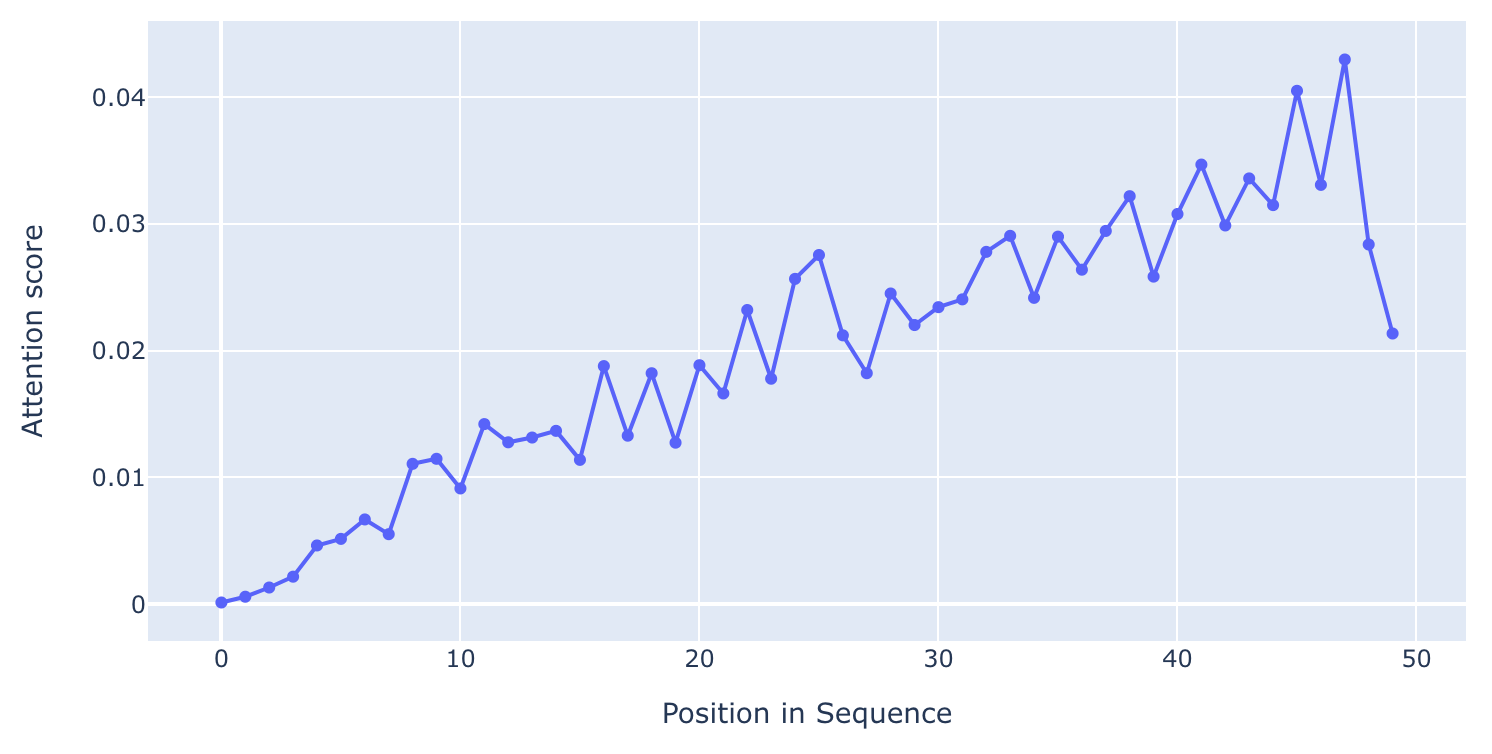
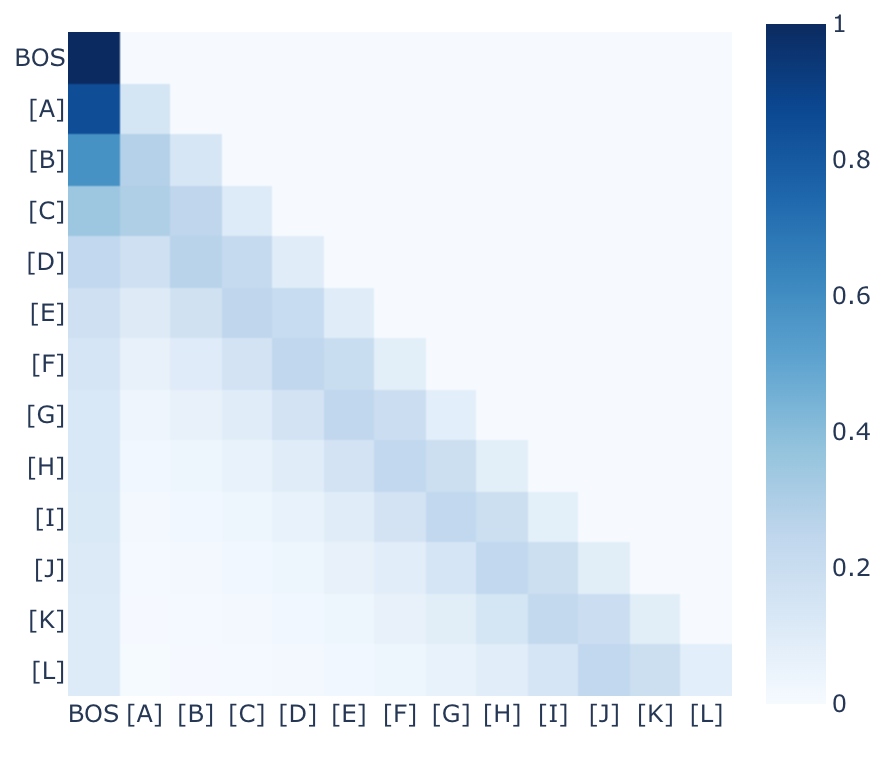
'Recency bias' in an induction head
The induction head in a 2-layer attention-only transformer model has a slight bias towards tokens later in the context compared to earlier. Interestingly, its notion of position appears to not depend on positional embeddings, or any specific output from an attention head in the previous layer.
Induction head circuits for longer sequences
In a 2-layer attention-only transformer model, an induction head can combine with an "averaging" head that stores some kind of average over the previous ~4-5 tokens to produce a circuit that can predict the next token in repeated sequences of length 2 to 5.
The previous token head and the "look-back-two" head
A few plots on previous token heads, a discussion of how they work and a comparison to a similar type of attention head -- a "look-back-two" head.
Positional Embeddings in a 2-layer attention-only transformer model
The position embeddings in a 2-layer attention-only transformer model arrange themselves into a helical structure. This presumably allows the model to generate QK matrices to move a few positions in relative terms with a similar transformation for all positions. The positional embeddings at positions 0 and 1023 have special properties.
The Initial Magnetic Field Distribution in AB Stars
Published in Farrell et al. (2022), The Astrophysical Journal, Volume 938, Issue 1
Numerical experiments to help understand cause and effect in massive star evolution
Published in Farrell et al. (2022), Monthly Notices of the Royal Astronomical Society, Volume 512, Issue 3
Is GW190521 the merger of black holes from the first stellar generations?
Published in Farrell et al. (2021), Monthly Notices of the Royal Astronomical Society: Letters, Volume 502, Issue 1
SNAPSHOT: connections between internal and surface properties of massive stars
Published in Farrell et al. (2020), Monthly Notices of the Royal Astronomical Society, Volume 495, Issue 4
The uncertain masses of progenitors of core-collapse supernovae and direct-collapse black holes
Published in Farrell et al. (2020), Monthly Notices of the Royal Astronomical Society, Volume 494, Issue 1
Impact of binary interaction on the evolution of blue supergiants
Published in Farrell et al. (2019), Astronomy & Astrophysics, Volume 621