Posts tagged sae
Unlearning with sparse autoencoders
We trained sparse autoencoders on the open-source language model Pythia-2.8b to use for unlearning Harry Potter related knowledge. We can successfully unlearn significant levels of Harry Potter related knowledge with little to no side effects.
Experiments with an alternative method to promote sparsity in sparse autoencoders
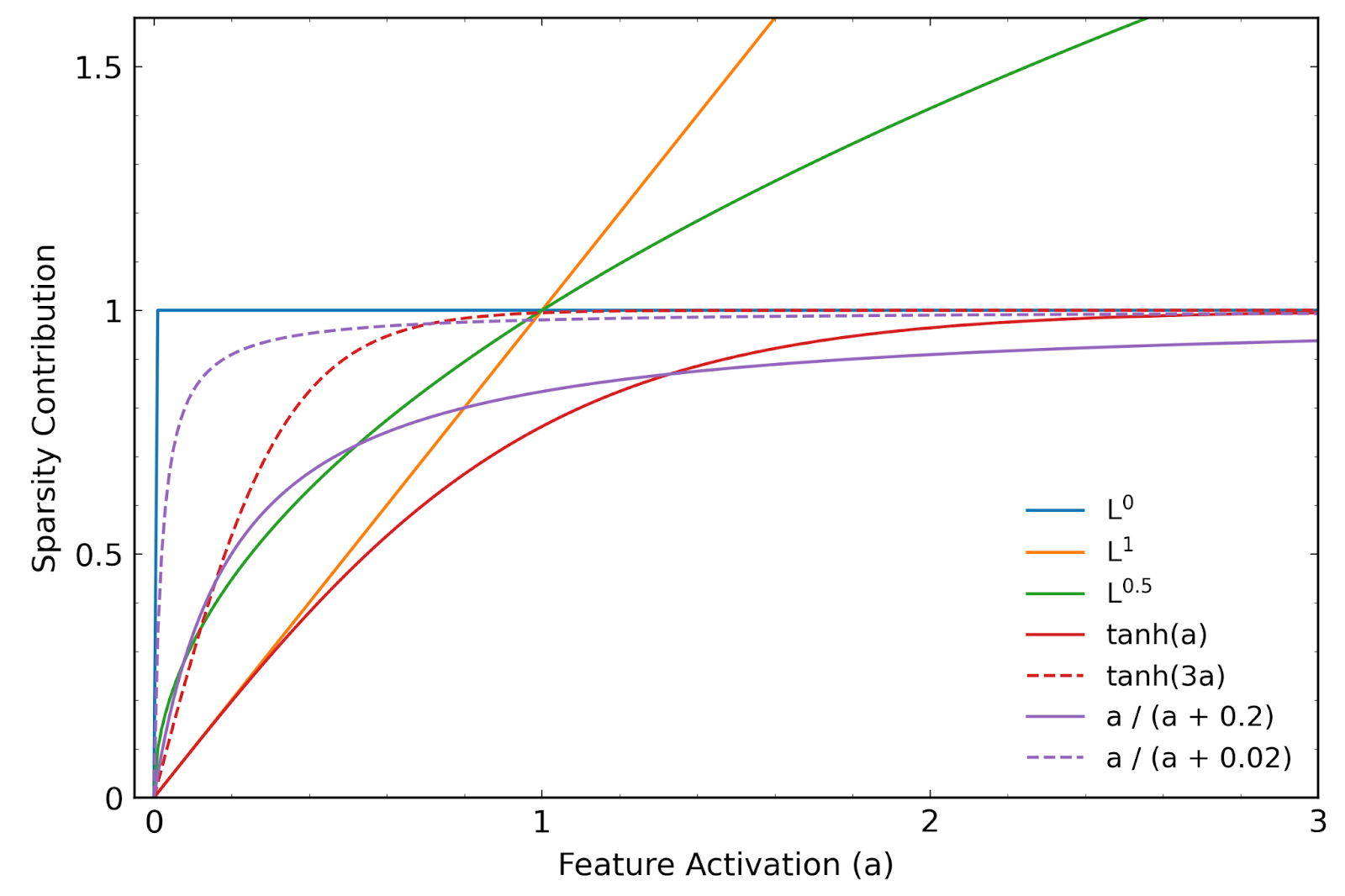
I experimented with alternatives to the standard L1 penalty used to promote sparsity in sparse autoencoders (SAEs). I found that including terms based on an alternative differentiable approximation of the feature sparsity in the loss function was an effective way to generate sparsity in SAEs trained on the residual stream of GPT2-small.
Experiments with Sparse Autoencoders on Attention Heads
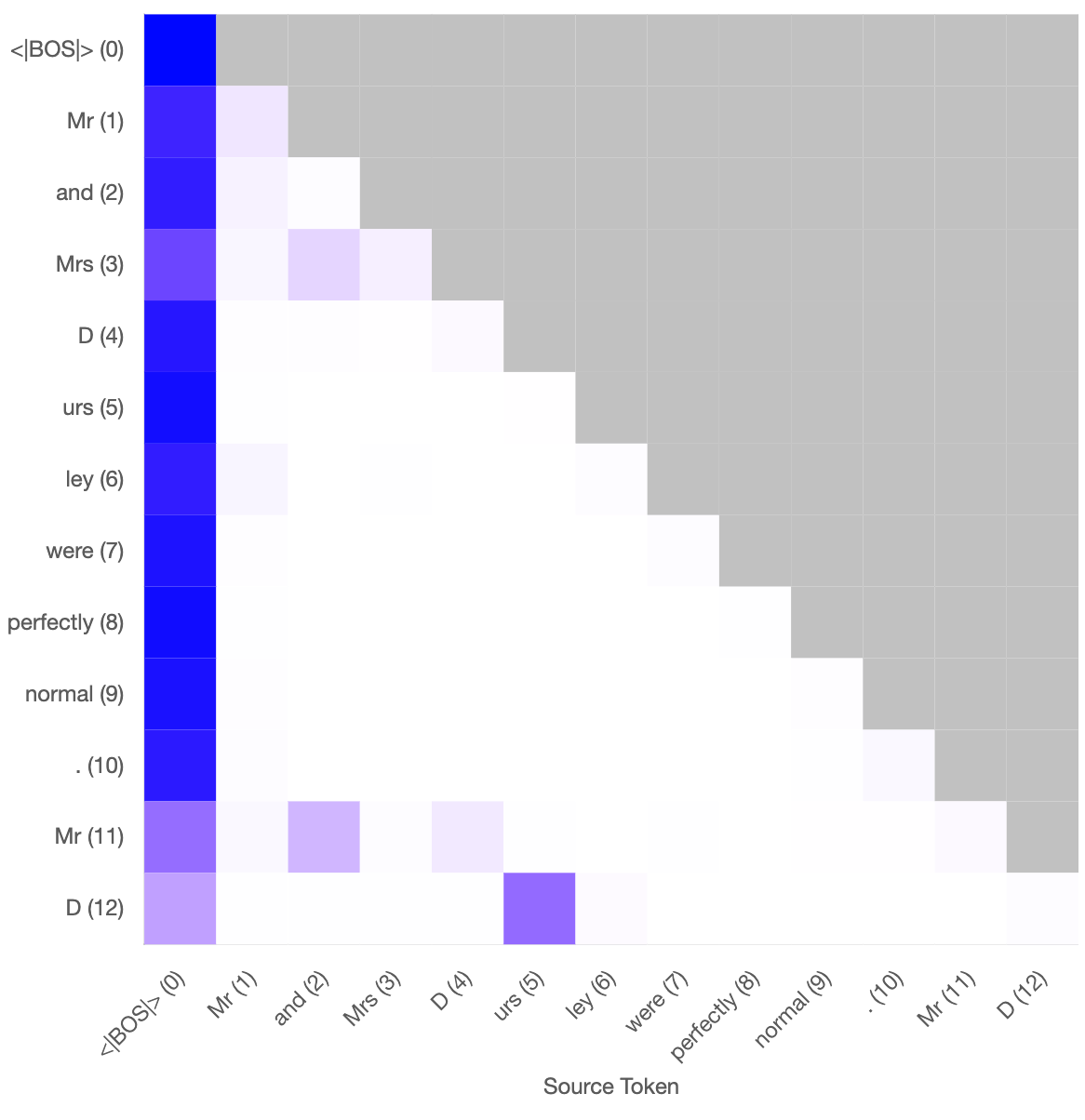
I trained sparse autoencoders on the key and query vectors of previous token heads and induction heads of attn-only-2l and gpt2-small and found interpretable features which I could intervene on in a predictable and interpretable way.